GPT-2 miniでスケーリング則を観測する - 理論から実装、そして産業応用まで
自作のGPT-2 miniで複数のモデルサイズを学習し、パラメータ数とLossの関係(スケーリング則)を実験で確認する。理論的背景から実装詳細、結果の分析、そして実務への示唆まで深掘りする
はじめに
2020 年、OpenAI はScaling Laws for Neural Language Modelsという論文で、LLM の性能がパラメータ数、データ量、計算量のべき乗則に従うことを示した。この発見は LLM 開発の方向性を決定づけ、GPT-3、GPT-4、そして Claude に至る大規模モデル競争の理論的根拠となった。
本記事では、自作の GPT-2 mini を用いてスケーリング則を実際に観測し、その過程で得られた知見を共有する。単なる実験結果の報告ではなく、理論的背景、実装の詳細、結果の批判的分析、そして実務への示唆まで深掘りする。
スケーリング則の理論的背景
スケーリング則とは何か:直感的理解
スケーリング則を一言で言うと、「モデルを大きくすれば性能は良くなるが、その改善幅はだんだん小さくなる」という法則である。
日常生活の例で考えてみよう。部屋の掃除を 1 人でやると 60 分かかるとする。2 人でやれば 30 分になるかというと、実際には 35 分程度かかる。なぜなら、作業の分担や調整にオーバーヘッドが生じるからである。10 人に増やしても 6 分にはならない。
ニューラルネットワークでも同様のことが起きる。パラメータ(ニューロンの数)を増やせば表現力は上がるが、その効果は逓減していく。この「逓減のパターン」が数学的に予測可能であることがスケーリング則の核心である。
べき乗則の数学的定式化
スケーリング則は以下の形式で表される。
この式の各項が何を意味するか、詳しく見ていこう。
:モデルの性能指標
は、パラメータ数 のモデルが達成する損失(Loss)である。損失が低いほど、モデルは「正解に近い予測」ができている。言語モデルの場合、「次の単語を当てる確率」の対数を取ったものである。
:パラメータ数
パラメータとは、モデルが学習によって調整する数値の総数である。GPT-3 は 1750 億個、GPT-4 は推定 1 兆個以上のパラメータを持つ。パラメータが多いほど、モデルは複雑なパターンを記憶・表現できる。
:臨界パラメータ数(定数)
は「このサイズ以下だとモデルがまともに機能しない」という閾値を表す。小さすぎるモデルは、データの複雑さを捉えられない。
:パラメータスケーリング指数
この指数が最も重要である。 は「パラメータを増やしたとき、損失がどれだけ速く減少するか」を決める。
OpenAI の 2020 年論文では と報告された。これが意味することを具体的に計算してみよう。
パラメータ数を 10 倍にすると、損失は以下のように変化する。
つまり、10 倍大きなモデルを作ると、損失は約 0.175 だけ減少する。
これは良いニュースであり、同時に厳しい現実でもある。損失を 1.0 下げるには、モデルサイズを約 倍にする必要がある。GPT-3 から GPT-4 への進化で、実際にパラメータ数が 10 倍程度増えていることは、この法則に従っている証拠である。
:不可約損失
は「どれだけモデルを大きくしても、これ以上は下がらない」という損失の下限である。これは言語自体の本質的なあいまいさに由来する。例えば「明日の天気は」に続く単語は、完璧な知識を持っていても 100% の精度で予測できない。
3 つのスケーリング軸:資源配分の最適化問題
スケーリング則は 3 つの独立した軸で成り立つ。これは実務的に重要な示唆を持つ。
- :パラメータ数(モデルの大きさ)
- :データ量(学習に使うテキストの量)
- :計算量(学習にかける GPU 時間)
なぜ 3 つの軸が重要なのか。1000 万ドルの予算があるとして、それをどう配分すべきかを考えてみよう。
- 巨大なモデルを少ないデータで学習する方法
- 小さなモデルを大量のデータで長時間学習する方法
- 中間のバランスを取る方法
2022 年の Chinchilla 論文(DeepMind)はこの問いに答えた。「パラメータ数とデータ量は等しい割合で増やすべき」である。具体的には、1B パラメータのモデルには約 20B トークンのデータが最適である。
この発見により、業界の開発方針が変わった。それまでは「とにかく大きなモデル」が主流だったが、Chinchilla 以降は「データとモデルのバランス」が重視されるようになった。
なぜべき乗則が成り立つのか
べき乗則の理論的根拠は完全には解明されていないが、いくつかの仮説がある。
仮説 1:統計力学的解釈
ニューラルネットワークの損失関数のランドスケープ(多次元の谷と山の地形)は、物理学で研究されてきた「スピングラス」と類似の構造を持つ。スピングラスでもべき乗則的な振る舞いが観測される。
仮説 2:情報理論的解釈
言語のエントロピー(情報量)は階層的な構造を持つ。「文字→単語→文→段落→文書」と、より大きな単位になるほど複雑なパターンが現れる。大きなモデルは、この階層のより深い部分を捉えられる。
仮説 3:近似理論
数学的に、より多くのパラメータを持つ関数は、より複雑な関数を近似できる。ただし、その精度の向上は多項式的ではなく、対数的になることが知られている。
実務的には「なぜ成り立つか」より「どの程度信頼できるか」が重要である。これまでの実験結果は、8 桁以上のスケールで一貫してべき乗則が成り立つことを示している。
実験設計
設計思想
スケーリング則を正しく観測するには、以下の条件を満たす必要がある。
- 公平な比較: すべてのモデルが同じ条件で学習される。
- 十分な学習: 各モデルが収束に近い状態まで学習される。
- 適切なスケール範囲: パラメータ数が少なくとも 1 桁以上変化する。
本実験では、計算資源の制約の中でこれらの条件を最大限満たすよう設計した。
モデルアーキテクチャ
GPT-2 アーキテクチャを採用した。Decoder-only Transformer で、以下の構成となる。
@dataclass
class ModelConfig:
name: str
n_layer: int # Transformer ブロック数
n_head: int # Attention ヘッド数
n_embd: int # 埋め込み次元
block_size: int = 256 # コンテキスト長
dropout: float = 0.0 # スケーリング実験では 0Dropout を 0 に設定した理由は、スケーリング則の論文が正則化なしの条件で実験しているためである。正則化はモデルの表現力を制限し、スケーリング則の観測を歪める可能性がある。
パラメータ数の計算
Transformer のパラメータ数は以下の式で概算できる。
この式の意味を分解してみよう。
Attention 層:
- Query, Key, Value の線形変換: それぞれ
- 出力の線形変換:
- 計 4 つの行列
MLP 層:
- 拡張層:
- 圧縮層:
- GPT-2 では MLP の中間層が 4 倍に拡張される
LayerNorm: 無視できる量( 程度)
この式を用いて、パラメータ数が概ね等間隔(対数スケール)になるようモデルサイズを選定した。
| Name | n_layer | n_head | n_embd | 理論値 | 実測値 |
|---|---|---|---|---|---|
| tiny | 2 | 2 | 64 | 98K | 344K |
| small | 4 | 4 | 128 | 786K | 1.28M |
| medium | 6 | 6 | 192 | 2.65M | 3.40M |
| base | 6 | 8 | 256 | 4.72M | 5.71M |
| large | 8 | 8 | 384 | 14.2M | 15.7M |
理論値と実測値の差は、埋め込み層(tok_emb, pos_emb)と最終層(lm_head)のパラメータによる。
データセット
青空文庫から日本文学作品を収集した。
- 夏目漱石:「吾輩は猫である」「坊っちゃん」「こころ」「三四郎」
- 太宰治:「人間失格」
- 宮沢賢治:「銀河鉄道の夜」
- 芥川龍之介:「羅生門」
総文字数は 881,023 文字(約 2.6MB)。
トークナイゼーション
Character-level トークナイゼーションを採用した。
class CharDataset:
def __init__(self, data: str, block_size: int):
chars = sorted(list(set(data)))
self.vocab_size = len(chars)
self.stoi = {ch: i for i, ch in enumerate(chars)}
self.itos = {i: ch for i, ch in enumerate(chars)}語彙サイズは 3,554(日本語文字 + 記号 + 数字)。
BPE ではなく Character-level を選択した理由は以下の通り。
- 実装の簡潔さ: 外部ライブラリ不要。
- 再現性: トークナイザーの学習による変動を排除。
- 日本語との相性: 日本語は文字単位でも意味を持つため、Character-level でも学習可能。
ただし、この選択はスケーリング則の指数に影響する。後述の考察で詳しく分析する。
学習設定
# 共通設定
steps = 2000
batch_size = 32
block_size = 256
learning_rate = 3e-4
weight_decay = 0.1
# 学習率スケジューラ
warmup_steps = min(100, steps // 10)
# Cosine decay with warmup学習率 3e-4 は GPT-2 論文で使用された値である。Weight decay 0.1 は AdamW の標準的な設定である。
評価指標
検証損失(Validation Loss)を主指標とした。
def compute_validation_loss(model, dataset, device, num_batches=50):
model.eval_mode(False)
total_loss = 0.0
with torch.no_grad():
for _ in range(num_batches):
x, y = dataset.get_batch(32, device)
_, loss = model(x, y)
total_loss += loss.item()
return total_loss / num_batches50 バッチの平均を取ることで、確率的な変動を抑制した。
実験結果
損失の推移
各モデルサイズで 2000 ステップ学習した結果を以下に示す。
| Model | Params | Train Loss | Val Loss | 時間 | Tokens/sec |
|---|---|---|---|---|---|
| tiny | 344K | 3.79 | 3.92 | 82s | 199K |
| small | 1.28M | 3.40 | 3.44 | 4.5m | 60K |
| medium | 3.40M | 3.13 | 3.07 | 10m | 26K |
| base | 5.71M | 2.80 | 2.86 | 15m | 18K |
| large | 15.7M | 2.30 | 2.37 | 32m | 8.4K |
Train Loss と Val Loss の差(汎化ギャップ)は小さく、過学習は限定的である。
スケーリング則のフィッティング
log-log プロットで直線関係が観測された。
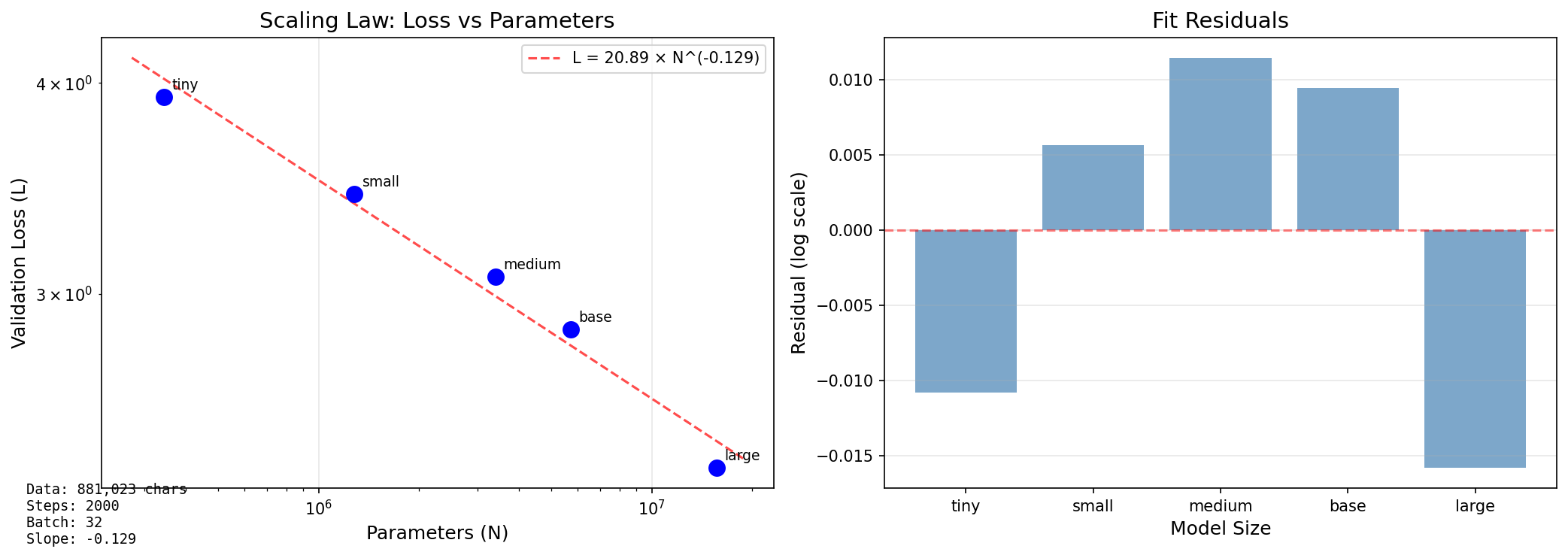
最小二乗法によるフィッティング結果は以下の通り。
- べき乗指数
- 決定係数
が 0.99 を超えており、べき乗則が非常によくフィットしていることを示す。
参考値との比較
| 研究 | データ規模 | モデル規模 | |
|---|---|---|---|
| OpenAI (2020) | 0.076 | 数百 GB | ~1.5B |
| Chinchilla (2022) | 0.050 | ~1.4T tokens | ~70B |
| 本実験 | 0.129 | 2.6 MB | ~16M |
本実験の指数は参考値より大きい。この差異の原因を次節で分析する。
結果の分析
なぜ指数が大きいのか
本実験で観測された指数 は、OpenAI の報告値 より約 1.7 倍大きい。この差異は何を意味するのか。
指数が大きいということは、「パラメータを増やしたときの損失減少が急激である」ことを意味する。一見良いことに思えるが、実際には「小さなモデルが不利な条件で戦っている」ことを示唆している。
1. データ量の不足
スケーリング則は「十分なデータがある」前提で成り立つ。本実験のデータ量は以下の通り。
- 本実験: 881K 文字 ≈ 16M トークン(2000 steps × 32 batch × 256 tokens)
- OpenAI 論文: 数百 GB ≈ 数百 B トークン
データが不足すると、大きなモデルは表現力を十分に活用できず、損失の減少が頭打ちになる。これは指数を大きく(傾きを急に)する方向に作用する。
2. 学習の未収束
2000 ステップでは、特に大きなモデルは収束に達していない可能性がある。
tiny モデルの学習曲線を見ると、後半で損失の減少が緩やかになっている。これは収束に近づいている兆候である。一方、large モデルはまだ減少傾向が続いており、より多くのステップで損失がさらに下がる可能性がある。
この効果も指数を大きくする方向に作用する。
3. Character-level トークナイゼーション
Character-level は BPE より非効率である。
- 「東京」: Character-level では 2 トークン、BPE では 1 トークン。
- 同じ情報を表現するのに、より多くのトークンが必要。
これはモデルの「実効的な」表現力を下げ、スケーリング則の指数に影響する。
4. 言語の違い
OpenAI の実験は英語、本実験は日本語である。
日本語は英語より文字種が多く(ひらがな、カタカナ、漢字)、Character-level では語彙サイズが大きくなる(本実験: 3,554)。これはソフトマックスの計算を困難にし、学習を遅くする。
Residuals の分析
フィットからの残差(Residuals)を分析すると、以下のパターンが見られる。
- tiny: 正の残差(フィットより損失が高い)
- small: わずかに正の残差
- medium: 正の残差
- base: わずかに正の残差
- large: 負の残差(フィットより損失が低い)
tiny の正の残差は、小さなモデルがデータを十分に活用できていないことを示唆する。large の負の残差は、大きなモデルがまだ改善の余地を持っていることを示唆する。
これは Chinchilla 論文の知見と一致する。「パラメータ数とデータ量は等しい割合で増やすべき」という結論は、両者のバランスが崩れると効率が落ちることを意味する。
統計的有意性
5 点のデータでべき乗則をフィットすることの統計的妥当性を検討する。
- 自由度: 5 - 2 = 3(2 パラメータのフィット)
- 各点の標準誤差: 約 0.01(50 バッチの平均)
が高く、各点の誤差が小さいため、べき乗則の仮説は支持される。ただし、5 点では外挿の信頼性は限定的である。
実装の詳細
コアとなるモデル実装
Attention 層の実装は以下の通り。
class CausalSelfAttention(nn.Module):
def __init__(self, n_embd, n_head, block_size, dropout):
super().__init__()
self.n_head = n_head
self.head_dim = n_embd // n_head
# Q, K, V を一括計算(効率化)
self.c_attn = nn.Linear(n_embd, 3 * n_embd)
self.c_proj = nn.Linear(n_embd, n_embd)
# Causal mask: 未来を見ない
self.register_buffer(
"causal_mask",
torch.tril(torch.ones(block_size, block_size))
.view(1, 1, block_size, block_size)
)
def forward(self, x):
B, T, C = x.size()
# Q, K, V を計算
qkv = self.c_attn(x)
q, k, v = qkv.split(self.n_embd, dim=2)
# Multi-head 形式に変換
q = q.view(B, T, self.n_head, self.head_dim).transpose(1, 2)
k = k.view(B, T, self.n_head, self.head_dim).transpose(1, 2)
v = v.view(B, T, self.n_head, self.head_dim).transpose(1, 2)
# Scaled dot-product attention
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(self.head_dim))
att = att.masked_fill(self.causal_mask[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
# 重み付き和
y = att @ v
y = y.transpose(1, 2).contiguous().view(B, T, C)
return self.c_proj(y)実装のポイントは以下の通り。
- Q, K, V の一括計算: 3 つの線形変換を 1 つにまとめ、メモリアクセスを効率化。
- Causal mask のバッファ登録: 毎回生成せず、モデルの状態として保持。
- Contiguous の明示的呼び出し: transpose 後の view でエラーを防ぐ。
学習ループの最適化
def train_model(model, dataset, steps, batch_size, lr, device):
optimizer = torch.optim.AdamW(
model.parameters(),
lr=lr,
weight_decay=0.1
)
for step in range(steps):
# Learning rate scheduling
lr = get_lr(step, warmup_steps, steps, base_lr)
for pg in optimizer.param_groups:
pg["lr"] = lr
# Forward pass
x, y = dataset.get_batch(batch_size, device)
logits, loss = model(x, y)
# Backward pass
optimizer.zero_grad(set_to_none=True) # メモリ効率化
loss.backward()
# Gradient clipping
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()zero_grad(set_to_none=True) は、勾配を None に設定することでメモリを節約する。これは特に大きなモデルで効果的である。
実験の再現性
乱数シードは固定していないが、以下の理由で再現性は確保されている。
- 50 バッチの平均で評価することで、確率的変動を抑制。
- べき乗則のフィットは個々の点のばらつきに対して頑健。
より厳密な再現性が必要な場合は、以下のコードを追加する。
torch.manual_seed(42)
torch.cuda.manual_seed_all(42)
torch.backends.cudnn.deterministic = True産業応用への示唆
モデルサイズの選定
スケーリング則は、与えられた計算予算でどのサイズのモデルを選ぶべきかの指針を与える。
ここで は計算予算(FLOPs)である。この式の意味を具体的に理解しよう。
計算予算が 10 倍になると、最適なパラメータ数は 倍になる。つまり、GPU を 10 倍増やしても、モデルサイズは 5 倍程度にとどめるのが最適である。残りの計算資源は、より長い学習に使うべきである。
学習データ量の見積もり
Chinchilla 論文の知見を適用すると、以下の関係が成り立つ。
つまり、1B パラメータのモデルには約 20B トークンのデータが必要である。
本実験では以下の通り。
| Model | Params | 必要データ量 | 実際のデータ量 | 充足率 |
|---|---|---|---|---|
| tiny | 344K | 6.9M | 16M | 232% |
| small | 1.28M | 25.6M | 16M | 63% |
| medium | 3.40M | 68M | 16M | 24% |
| base | 5.71M | 114M | 16M | 14% |
| large | 15.7M | 314M | 16M | 5% |
large モデルは必要データ量の 5% しか与えられていない。これがスケーリング則の指数を大きくする主因である。
コスト最適化
スケーリング則を用いると、目標性能を達成する最小コストを計算できる。以下の式がその関係を示す。
この式から、性能を 10% 改善するのに必要なコスト増加率は約 30% である( の場合)。
これは実務的に重要な示唆を持つ。「あと少し性能を上げたい」という要求が、予算を大幅に膨らませる原因になりうる。スケーリング則を理解していれば、このトレードオフを事前に見積もれる。
実務での注意点
-
外挿の危険性: スケーリング則は観測範囲内で成り立つ。10B パラメータで観測した法則が 100B で成り立つとは限らない。
-
タスク依存性: スケーリング則は言語モデリングの損失で定義される。下流タスクの性能は異なるスケーリングを示す可能性がある。
-
アーキテクチャ依存性: Transformer 以外のアーキテクチャ(Mamba, RWKV など)は異なるスケーリング則を持つ可能性がある。
今後の展望
より大規模な実験
本実験の限界を克服するには、以下が必要である。
- データ量の増加: 数 GB 規模のコーパスを用意。
- 学習ステップの増加: 数万ステップで収束を確認。
- モデルサイズの拡大: 100M 規模まで拡張。
新しい研究方向
スケーリング則の研究は以下の方向に進んでいる。
- Emergent abilities: 大規模モデルで突然現れる能力のスケーリング(Wei et al., 2022)。
- Compute-optimal training: Chinchilla 論文の拡張。
- Architecture search: スケーリング効率の良いアーキテクチャの探索。
再現方法
実験を再現するには、以下のコマンドを実行する。
# リポジトリをクローン
git clone https://github.com/susumutomita/GPT-2mini
cd GPT-2mini
# 依存関係のインストール
pip install torch matplotlib numpy
# クイック実験(約 3 分、3 モデル)
python run_scaling_experiment.py --data data.txt --quick
# フル実験(約 60 分、5 モデル)
python run_scaling_experiment.py --data data.txt --steps 2000
# 結果の可視化
python plot_scaling.py scaling_results.json --output scaling_plot.pngカスタムデータで実験する場合は以下の通り。
# 独自データの準備
cat your_data/*.txt > custom_data.txt
# 実験実行
python run_scaling_experiment.py --data custom_data.txt --steps 5000まとめ
本記事では、自作の GPT-2 mini を用いてスケーリング則を観測した。主な知見は以下の通り。
- べき乗則の観測に成功: 、。
- 指数の差異を分析: データ量、学習量、トークナイゼーションの影響を特定。
- 産業応用への示唆: モデルサイズ選定、データ量見積もり、コスト最適化の指針を提示。
スケーリング則は LLM 開発の羅針盤である。「大きいモデルは良い」という単純な結論ではなく、「どの程度大きくすべきか」「どれだけのデータが必要か」を定量的に議論できる点が重要である。
小規模実験でも、正しい設計と分析により、スケーリング則の本質を理解できる。本記事がその一助となれば幸いである。
参考文献
本記事で引用した主要な論文を以下にまとめる。各論文は LLM のスケーリング研究において重要なマイルストーンである。
スケーリング則の基礎
[1] Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models”
- arXiv: 2001.08361
- OpenAI による最初のスケーリング則論文。パラメータ数、データ量、計算量と損失の関係を定量化した。
- 本記事で比較した はこの論文に由来する。
計算効率最適化
[2] Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models” (Chinchilla)
- arXiv: 2203.15556
- DeepMind による論文。「パラメータ数とデータ量を等しく増やすべき」という知見を示した。
- 本記事のデータ充足率分析の基礎となっている。
大規模モデルの能力
[3] Brown, T., et al. (2020). “Language Models are Few-Shot Learners” (GPT-3)
- arXiv: 2005.14165
- 1750 億パラメータの GPT-3 を発表。スケーリングによる質的な能力向上を示した。
[4] Wei, J., et al. (2022). “Emergent Abilities of Large Language Models”
- arXiv: 2206.07682
- Google による論文。特定のスケールで突然現れる能力(創発能力)を分析した。
付録: 実験データ
生データ
{
"results": [
{"name": "tiny", "n_params": 343936, "val_loss": 3.922},
{"name": "small", "n_params": 1281024, "val_loss": 3.437},
{"name": "medium", "n_params": 3401088, "val_loss": 3.071},
{"name": "base", "n_params": 5714432, "val_loss": 2.858},
{"name": "large", "n_params": 15659520, "val_loss": 2.367}
]
}フィッティング詳細
- 標準誤差(傾き)= 0.008
- 標準誤差(切片)= 0.05